在Prometheus监控中,对于采集到服务端的指标,称为metrics数据。metrics指标为时间序列数据,它们按相同的时序,以时间维度来存储连续数据的集合。
metrics有自定义的一套数据格式,不管对于日常运维管理或者监控开发来说,了解并对其熟练掌握都是非常必要的,本文将对此进行详细介绍。
1、metric组成
每个metrics数据都包含几个部分:指标名称、标签和采样数据。
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
指标名称
用于描述收集指标的性质,其名称应该具有语义化,可以较直观的表示一个度量的指标。名称格式可包括ASCII字符、数字、下划线和冒号。
如:node_cpu
标签
时间序列标签为key/value格式,它们给Prometheus数据模型提供了维度,通过标签可以区分不同的实例,
如:node_network_receive_bytes_total{device="eth0"} #表示eth0网卡的数据
通过标签 ,Prometheus可以在不同维度上对一个或一组数据进行查询处理。标签名称由 ASCII 字符,数字,以及下划线组成, 其中 __ 开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。标签可来自被监控的资源,也可由Prometheus在抓取期间和之后添加。
采样数据
按照某个时序以时间维度采集的数据,其值包含:
一个float64值
一个毫秒级的unix时间戳
2、Mtrics格式
结合以上这些元素,Prometheus的时间序列统一使用以下格式来表示。
<metric name>{<label name>=<label value>, ...}
下面为一个node-exporter暴露的数据指标样本(http://192.168.75.162:9100/metrics):
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 409360.94
node_cpu_seconds_total{cpu="0",mode="iowait"} 0.37
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.03
node_cpu_seconds_total{cpu="0",mode="softirq"} 3.56
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 49.32
node_cpu_seconds_total{cpu="0",mode="user"} 1366.39
第一个#是指标的说明介绍,第二个# 代表指标的类型,此为必须项且格式固定,TYPE+指标名称+类型。node_cpu_seconds_total为指标名称,{}里面为标签, 它标明了当前指标样本的特征和维度,最后面的数值则是该样本的具体值。
3、Metric类型
Prometheus的时序数据分为Counter(计数器),Gauge(仪表盘),Histogram(直方图),Summary(摘要)四种类型。
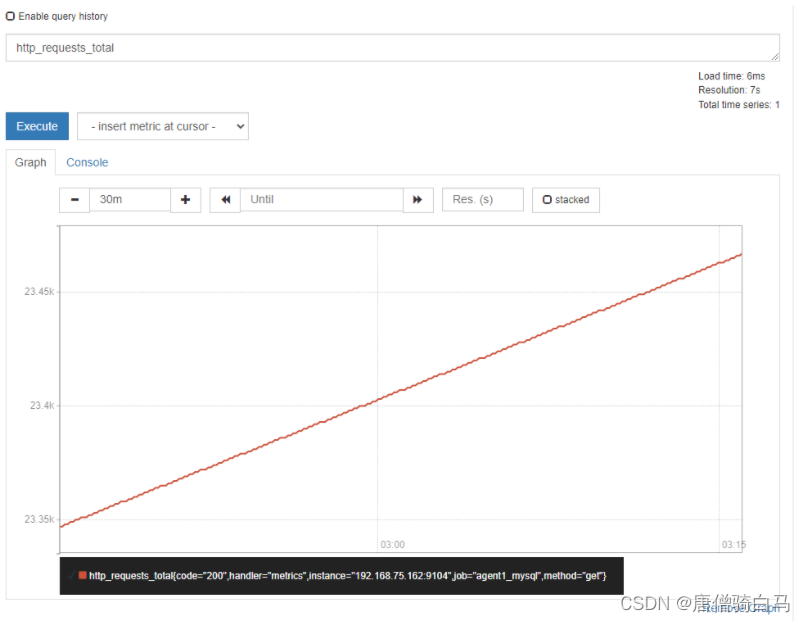
3.1 Counter:只增不减的计数器
counter类型的指标与计数器一样,会按照某个趋势一直变化(一般是增加),我们往往用它记录服务请求总量、错误总数等。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
如下图展示就是一个counter类型的metrics数据采集,采集的是Prometheus的接口访问量,可看到数值一直在向上增加。
PromQL内置的聚合操作和函数可以让用户对这些数据进行进一步的分析:
例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
3.2 Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree_bytes
对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。例如,计算CPU温度在两个小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_files_free{job="agent1"}[1h], 4 * 3600)
3.3 使用Histogram和Summary分析数据分布情况
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在0~10ms之间的请求数有多少而10~20ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
例如,指标prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。 它记录了Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.# TYPE prometheus_tsdb_wal_fsync_duration_seconds summaryprometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
在Prometheus Server自身返回的样本数据中,我们还能找到类型为Histogram的监控指标prometheus_tsdb_compaction_chunk_range_bucket。
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction# TYPE prometheus_tsdb_compaction_chunk_range histogramprometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09prometheus_tsdb_compaction_chunk_range_count 780
与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以count作为后缀)以及其值的总量(以sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择。
上一篇:Prometheus监控实战系列三:配置介绍
下一篇:Prometheus监控实战系列五:PromQL语法(上)