文章目录
- 前言
- 一、安装AlertManager
- 1、下载
- 2、安装AlertManager
- 二、配置AlertManager
- 1、配置Prometheus
- 2、配置通知路由和接收器
- 2.1、global
- 2.2、templates
- 2.3、route
- 2.4、receivers
- 2.5、inhibit_rules
- 2.6、配置示例(邮件告警)
- 2.6.1配置alertmanager
- 2.6.2配置prometheus的rule_files
- 2.6.3配置记录规则和报警规则
前言
Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Email, Slack等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
Github地址:https://github.com/prometheus/alertmanager
最新版本:0.23.0
一、安装AlertManager
1、下载
下载地址列表页:https://github.com/prometheus/alertmanager/releases
0.23.0版本下载地址:https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz
2、安装AlertManager
将上一步下载的包上传至服务器
tar zvxf alertmanager-0.23.0.linux-amd64.tar.gz
mv alertmanager-0.23.0.linux-amd64 /usr/local/alertmanager
vi /etc/systemd/system/alertmanager.service
添加:
[Unit]
Description=Alertmanager
After=network.target
[Service]
Type=simple
#User=prometheus
#Group=prometheus
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--storage.path=/usr/local/alertmanager/data \
--web.listen-address=0.0.0.0:9093 \
--cluster.listen-address=0.0.0.0:9094 \
--log.level=info \
--log.format=logfmt
Restart=always
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable alertmanager && systemctl start alertmanager
访问http://172.16.10.171:9093/metrics
二、配置AlertManager
1、配置Prometheus
修改prometheus.yml配置文件,修改alerting的配置。
vi /usr/local/prometheus/prometheus.yml
将刚启动的alertmanager配置进去
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["172.16.10.171:9093"]
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "spring"
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: "/demo/actuator/prometheus"
static_configs:
- targets: ["192.168.100.88:7901"]
- job_name: "mysql8.x"
static_configs:
- targets: ["172.16.10.169:9104", "192.168.100.88:9104"]
- job_name: "nginx"
static_configs:
- targets: ["172.16.10.171:9913"]
- job_name: "node"
static_configs:
- targets: ["172.16.10.171:9100","172.16.10.160:9100","172.16.10.161:9100", "172.16.10.162:9100", "172.16.10.163:9100", "172.16.10.164:9100", "172.16.10.165:9100", "172.16.10.167:9100", "172.16.10.168:9100", "172.16.10.169:9100", "172.16.10.170:9100"]
- job_name: "alertmanager"
static_configs:
- targets: ["172.16.10.171:9093"]
systemctl restart prometheus
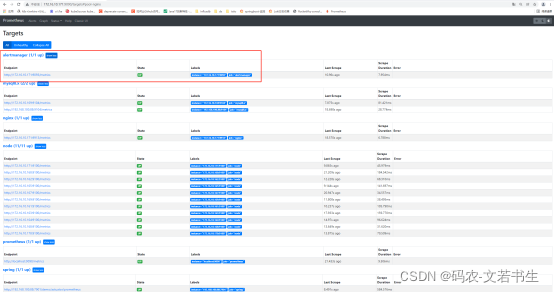
访问http://172.16.10.171:9090/targets
2、配置通知路由和接收器
alertmanager通过命令行标志和配置文件进行配置。命令行标志配置不可变的系统参数时,配置文件定义禁止规则,通知路由和通知接收器。
alertmanager.yml的配置信息包含以下几部分:
| global | 全局配置 |
|---|---|
| templates | 通知模板 |
| route | 路由配置 |
| receivers | 接收器配置 |
| inibit_rules | 抑制配置 |
2.1、global
global指定在所有其他配置上下文中有效的参数。还用作其他配置部分的默认设置。
global:
# 默认的SMTP头字段
[ smtp_from: <tmpl_string> ]
# 默认的SMTP smarthost用于发送电子邮件,包括端口号
# 端口号通常是25,对于TLS上的SMTP,端口号为587
# Example: smtp.example.org:587
[ smtp_smarthost: <string> ]
# 要标识给SMTP服务器的默认主机名
[ smtp_hello: <string> | default = "localhost" ]
# SMTP认证使用CRAM-MD5,登录和普通。如果为空,Alertmanager不会对SMTP服务器进行身份验证
[ smtp_auth_username: <string> ]
# SMTP Auth using LOGIN and PLAIN.
[ smtp_auth_password: <secret> ]
# SMTP Auth using PLAIN.
[ smtp_auth_identity: <string> ]
# SMTP Auth using CRAM-MD5.
[ smtp_auth_secret: <secret> ]
# 默认的SMTP TLS要求
# 注意,Go不支持到远程SMTP端点的未加密连接
[ smtp_require_tls: <bool> | default = true ]
# 用于Slack通知的API URL
[ slack_api_url: <secret> ]
[ victorops_api_key: <secret> ]
[ victorops_api_url: <string> | default = "https://alert.victorops.com/integrations/generic/20131114/alert/" ]
[ pagerduty_url: <string> | default = "https://events.pagerduty.com/v2/enqueue" ]
[ opsgenie_api_key: <secret> ]
[ opsgenie_api_url: <string> | default = "https://api.opsgenie.com/" ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ]
[ wechat_api_secret: <secret> ]
[ wechat_api_corp_id: <string> ]
# 默认HTTP客户端配置
[ http_config: <http_config> ]
# 如果告警不包括EndsAt,则ResolveTimeout是alertmanager使用的默认值,在此时间过后,如果告警没有更新,则可以声明警报已解除
# 这对Prometheus的告警没有影响,它们包括EndsAt
[ resolve_timeout: <duration> | default = 5m ]
2.2、templates
templates指定了从其中读取自定义通知模板定义的文件,最后一个文件可以使用一个通配符匹配器,如templates/*.tmpl
templates:
[ - <filepath> ... ]
2.3、route
route定义了路由树中的节点及其子节点。如果未设置,则其可选配置参数将从其父节点继承。
每个告警都会在已配置的顶级路由处进入路由树,该路由树必须与所有告警匹配(即没有任何已配置的匹配器),然后它会遍历子节点。如果continue设置为false,它将在第一个匹配的子项之后停止;如果continue设置为true,则告警将继续与后续的同级进行匹配。如果告警与节点的任何子节点都不匹配(不匹配的子节点或不存在子节点),则根据当前节点的配置参数来处理告警。
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
2.4、receivers
receivers是一个或多个通知集成的命名配置。建议通过webhook接收器实现自定义通知集成。
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
2.5、inhibit_rules
当存在与另一组匹配器匹配的告警(源)时,抑制规则会使与一组匹配器匹配的告警(目标)“静音”。目标和源告警的equal列表中的标签名称都必须具有相同的标签值。
在语义上,缺少标签和带有空值的标签是相同的。因此,如果equal源告警和目标告警都缺少列出的所有标签名称,则将应用抑制规则。
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
2.6、配置示例(邮件告警)
alertmanager_227">2.6.1配置alertmanager
vi /usr/local/alertmanager/alertmanager.yml
global:
smtp_smarthost: "smtp.163.com:25"
smtp_from: "18500971310@163.com"
smtp_auth_username: "18500971310@163.com"
smtp_auth_password: "12345678a"
smtp_require_tls: false
smtp_hello: "163.com"
resolve_timeout: 5m
route:
group_by: ['instance']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- send_resolved: true
to: '76775081@qq.com'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
systemctl restart alertmanager
prometheusrule_files_262">2.6.2配置prometheus的rule_files
修改prometheus.yml,添加rule_files配置
vi /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["172.16.10.171:9093"]
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "*rule.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "spring"
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: "/demo/actuator/prometheus"
static_configs:
- targets: ["192.168.100.88:7901"]
- job_name: "mysql8.x"
static_configs:
- targets: ["172.16.10.169:9104", "192.168.100.88:9104"]
- job_name: "nginx"
static_configs:
- targets: ["172.16.10.171:9913"]
- job_name: "node"
static_configs:
- targets: ["172.16.10.171:9100","172.16.10.160:9100","172.16.10.161:9100", "172.16.10.162:9100", "172.16.10.163:9100", "172.16.10.164:9100", "172.16.10.165:9100", "172.16.10.167:9100", "172.16.10.168:9100", "172.16.10.169:9100", "172.16.10.170:9100"]
- job_name: "alertmanager"
static_configs:
- targets: ["172.16.10.171:9093"]
systemctl restart prometheus
2.6.3配置记录规则和报警规则
配置告警规则
在prometheus.yml同级目录下创建两个报警规则配置文件node-exporter-record-rule.yml,node-exporter-alert-rule.yml。第一个文件用于记录规则,第二个是报警规则。
由于之前在prometheus.yml中已经引用了所有已rule结尾的文件,所以我们不用在修改prometheus.yml配置文件。
vi /usr/local/Prometheus/node-exporter-record-rule.yml
添加内容如下:
groups:
- name: node-exporter-record
rules:
- expr: up{job=~"node"}
record: node_exporter:up
labels:
desc: "节点是否在线, 在线1,不在线0"
unit: " "
job: "node-exporter"
- expr: time() - node_boot_time_seconds{}
record: node_exporter:node_uptime
labels:
desc: "节点的运行时间"
unit: "s"
job: "node-exporter"
##############################################################################################
# cpu #
- expr: (1 - avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))) * 100
record: node_exporter:cpu:total:percent
labels:
desc: "节点的cpu总消耗百分比"
unit: "%"
job: "node"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))) * 100
record: node_exporter:cpu:idle:percent
labels:
desc: "节点的cpu idle百分比"
unit: "%"
job: "node"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="iowait"}[5m]))) * 100
record: node_exporter:cpu:iowait:percent
labels:
desc: "节点的cpu iowait百分比"
unit: "%"
job: "node"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="system"}[5m]))) * 100
record: node_exporter:cpu:system:percent
labels:
desc: "节点的cpu system百分比"
unit: "%"
job: "node"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="user"}[5m]))) * 100
record: node_exporter:cpu:user:percent
labels:
desc: "节点的cpu user百分比"
unit: "%"
job: "node"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode=~"softirq|nice|irq|steal"}[5m]))) * 100
record: node_exporter:cpu:other:percent
labels:
desc: "节点的cpu 其他的百分比"
unit: "%"
job: "node"
##############################################################################################
##############################################################################################
# memory #
- expr: node_memory_MemTotal_bytes{job="node-exporter"}
record: node_exporter:memory:total
labels:
desc: "节点的内存总量"
unit: byte
job: "node"
- expr: node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:free
labels:
desc: "节点的剩余内存量"
unit: byte
job: "node"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:used
labels:
desc: "节点的已使用内存量"
unit: byte
job: "node"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemAvailable_bytes{job="node-exporter"}
record: node_exporter:memory:actualused
labels:
desc: "节点用户实际使用的内存量"
unit: byte
job: "node"
- expr: (1-(node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:used:percent
labels:
desc: "节点的内存使用百分比"
unit: "%"
job: "node"
- expr: ((node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:free:percent
labels:
desc: "节点的内存剩余百分比"
unit: "%"
job: "node"
##############################################################################################
# load #
- expr: sum by (instance) (node_load1{job="node-exporter"})
record: node_exporter:load:load1
labels:
desc: "系统1分钟负载"
unit: " "
job: "node"
- expr: sum by (instance) (node_load5{job="node-exporter"})
record: node_exporter:load:load5
labels:
desc: "系统5分钟负载"
unit: " "
job: "node"
- expr: sum by (instance) (node_load15{job="node-exporter"})
record: node_exporter:load:load15
labels:
desc: "系统15分钟负载"
unit: " "
job: "node"
##############################################################################################
# disk #
- expr: node_filesystem_size_bytes{job="node-exporter" ,fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:total
labels:
desc: "节点的磁盘总量"
unit: byte
job: "node"
- expr: node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:free
labels:
desc: "节点的磁盘剩余空间"
unit: byte
job: "node"
- expr: node_filesystem_size_bytes{job="node-exporter",fstype=~"ext4|xfs"} - node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:used
labels:
desc: "节点的磁盘使用的空间"
unit: byte
job: "node"
- expr: (1 - node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{job="node-exporter",fstype=~"ext4|xfs"}) * 100
record: node_exporter:disk:used:percent
labels:
desc: "节点的磁盘的使用百分比"
unit: "%"
job: "node"
- expr: irate(node_disk_reads_completed_total{job="node-exporter"}[1m])
record: node_exporter:disk:read:count:rate
labels:
desc: "节点的磁盘读取速率"
unit: "次/秒"
job: "node"
- expr: irate(node_disk_writes_completed_total{job="node-exporter"}[1m])
record: node_exporter:disk:write:count:rate
labels:
desc: "节点的磁盘写入速率"
unit: "次/秒"
job: "node"
- expr: (irate(node_disk_written_bytes_total{job="node-exporter"}[1m]))/1024/1024
record: node_exporter:disk:read:mb:rate
labels:
desc: "节点的设备读取MB速率"
unit: "MB/s"
job: "node"
- expr: (irate(node_disk_read_bytes_total{job="node-exporter"}[1m]))/1024/1024
record: node_exporter:disk:write:mb:rate
labels:
desc: "节点的设备写入MB速率"
unit: "MB/s"
job: "node"
##############################################################################################
# filesystem #
- expr: (1 -node_filesystem_files_free{job="node-exporter",fstype=~"ext4|xfs"} / node_filesystem_files{job="node-exporter",fstype=~"ext4|xfs"}) * 100
record: node_exporter:filesystem:used:percent
labels:
desc: "节点的inode的剩余可用的百分比"
unit: "%"
job: "node"
#############################################################################################
# filefd #
- expr: node_filefd_allocated{job="node-exporter"}
record: node_exporter:filefd_allocated:count
labels:
desc: "节点的文件描述符打开个数"
unit: "%"
job: "node"
- expr: node_filefd_allocated{job="node-exporter"}/node_filefd_maximum{job="node-exporter"} * 100
record: node_exporter:filefd_allocated:percent
labels:
desc: "节点的文件描述符打开百分比"
unit: "%"
job: "node"
#############################################################################################
# network #
- expr: avg by (environment,instance,device) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:bit:rate
labels:
desc: "节点网卡eth0每秒接收的比特数"
unit: "bit/s"
job: "node"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:bit:rate
labels:
desc: "节点网卡eth0每秒发送的比特数"
unit: "bit/s"
job: "node"
- expr: avg by (environment,instance,device) (irate(node_network_receive_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:packet:rate
labels:
desc: "节点网卡每秒接收的数据包个数"
unit: "个/秒"
job: "node"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:packet:rate
labels:
desc: "节点网卡发送的数据包个数"
unit: "个/秒"
job: "node"
- expr: avg by (environment,instance,device) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:error:rate
labels:
desc: "节点设备驱动器检测到的接收错误包的数量"
unit: "个/秒"
job: "node"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:error:rate
labels:
desc: "节点设备驱动器检测到的发送错误包的数量"
unit: "个/秒"
job: "node"
- expr: node_tcp_connection_states{job="node-exporter", state="established"}
record: node_exporter:network:tcp:established:count
labels:
desc: "节点当前established的个数"
unit: "个"
job: "node"
- expr: node_tcp_connection_states{job="node-exporter", state="time_wait"}
record: node_exporter:network:tcp:timewait:count
labels:
desc: "节点timewait的连接数"
unit: "个"
job: "node"
- expr: sum by (environment,instance) (node_tcp_connection_states{job="node-exporter"})
record: node_exporter:network:tcp:total:count
labels:
desc: "节点tcp连接总数"
unit: "个"
job: "node"
#############################################################################################
# process #
- expr: node_processes_state{state="Z"}
record: node_exporter:process:zoom:total:count
labels:
desc: "节点当前状态为zoom的个数"
unit: "个"
job: "node"
#############################################################################################
# other #
- expr: abs(node_timex_offset_seconds{job="node-exporter"})
record: node_exporter:time:offset
labels:
desc: "节点的时间偏差"
unit: "s"
job: "node"
#############################################################################################
- expr: count by (instance) ( count by (instance,cpu) (node_cpu_seconds_total{ mode='system'}) )
record: node_exporter:cpu:count
配置告警规则
vi /usr/local/prometheus/node-exporter-alert-rule.yml
配置内容如下:
groups:
- name: node-exporter-alert
rules:
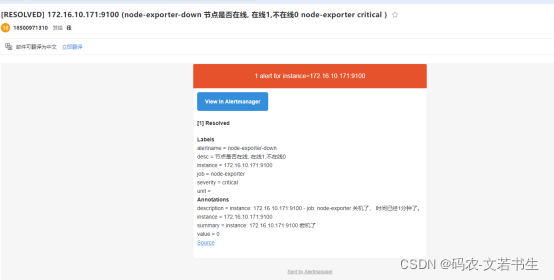
- alert: node-exporter-down
expr: node_exporter:up == 0
for: 1m
labels:
severity: 'critical'
annotations:
summary: "instance: {{ $labels.instance }} 宕机了"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} 关机了, 时间已经1分钟了。"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-cpu-high
expr: node_exporter:cpu:total:percent > 80
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} cpu 使用率高于 {{ $value }}"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} CPU使用率已经持续三分钟高过80% 。"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-cpu-iowait-high
expr: node_exporter:cpu:iowait:percent >= 12
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率高于 {{ $value }}"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} cpu iowait使用率已经持续三分钟高过12%"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-load-load1-high
expr: (node_exporter:load:load1) > (node_exporter:cpu:count) * 1.2
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} load1 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-memory-high
expr: node_exporter:memory:used:percent > 85
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-high
expr: node_exporter:disk:used:percent > 88
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} disk 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-read:count-high
expr: node_exporter:disk:read:count:rate > 3000
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} iops read 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-write-count-high
expr: node_exporter:disk:write:count:rate > 3000
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} iops write 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-read-mb-high
expr: node_exporter:disk:read:mb:rate > 60
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 读取字节数 高于 {{ $value }}"
description: ""
instance: "{{ $labels.instance }}"
value: "{{ $value }}"
- alert: node-exporter-disk-write-mb-high
expr: node_exporter:disk:write:mb:rate > 60
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 写入字节数 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-filefd-allocated-percent-high
expr: node_exporter:filefd_allocated:percent > 80
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 打开文件描述符 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-netin-error-rate-high
expr: node_exporter:network:netin:error:rate > 4
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包进入的错误速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-netin-packet-rate-high
expr: node_exporter:network:netin:packet:rate > 35000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包进入速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-netout-packet-rate-high
expr: node_exporter:network:netout:packet:rate > 35000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包流出速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-tcp-total-count-high
expr: node_exporter:network:tcp:total:count > 40000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} tcp连接数量 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-process-zoom-total-count-high
expr: node_exporter:process:zoom:total:count > 10
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 僵死进程数量 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-time-offset-high
expr: node_exporter:time:offset > 0.03
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} {{ $labels.desc }} {{ $value }} {{ $labels.unit }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
Systemctl restart prometheus
访问http://172.16.10.171:9090/alerts
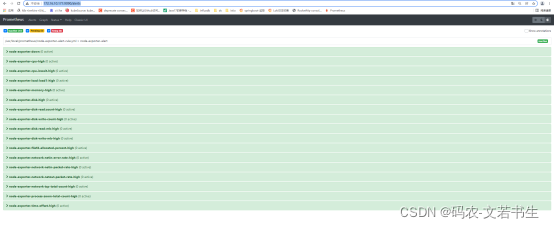
这说明配置成功了。
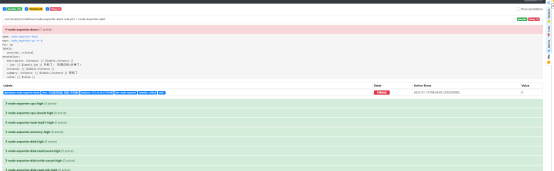
测试关掉一个node_exporter
systemctl stop node_exporter
等待1分钟左右,
先变成pending,再变成firing

过一会收到邮件
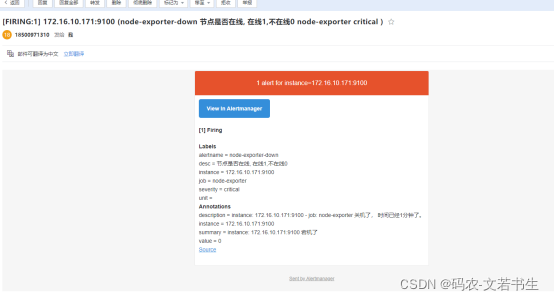
当重启后
systemctl restart node_exporter
会收到恢复邮件