摘要
Prometheus是继Kubernetes之后,第二个从云原生计算基金会(CNCF)毕业的项目。Prometheus是Google监控系统BorgMon类似实现的开源版,整套系统由监控服务、告警服务、时序数据库等几个部分,及周边生态的各种指标收集器(Exporter)组成,是在当下主流的云原生监控告警系统,Prometheus有这些特性:
- 开箱即用的各种服务发现机制,可以自动发现监控端点;
- 专为监控指标数据设计的高性能时序数据库TSDB;
- 强大易用的查询语言PromQL以及丰富的聚合函数;
- 可以配置灵活的告警规则,支持告警收敛(分组、抑制、静默)、多级路由等等高级功能;
- 生态完善,有各种现成的开源Exporter实现,实现自定义的监控指标也非常简单。

本博文将详细的介绍基于Prometheus的生产环境下的基础服务的监控与自定义服务的监控服务治理。帮助大家在项目生产环境中能够时间集监控与预警和自动化脚本处理等功能。
一、Prometheus的基础原理简介
二、Prometheus+Alertmanager实战
通过Prometheus+Alertmanager+docker(部署该服务,包括四个组件:Prometheus Server、Node Exporter、cAdvrisor、Grafana。)其他组件来进行相关的配置实战。
- Prometheus Server:Prometheus服务的主服务器 ;
- Node Exporter:收集Host硬件和操作系统的信息;
- cAdvrisor:负责收集Host上运行的容器信息;
- Grafana:用来展示Prometheus监控操作界面(给我们提供一个友好的web界面)
2.1 docker 运行组件
运行Node Server容器:该组件需要运行在所有需要监控的主机上,也就是,我这里三台服务器都需要执行下面的命令,运行此容器组件。
docker run -d -p 9100:9100 -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host --restart=always prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"每台服务器运行上述命令后,浏览器访问docker服务器的IP地址+9100端口,能够看到以下界面,即说明容器运行没有问题。看到的网页如下就表示部署成功了:

运行cAdvisor容器:CAdvrisor是负责收集Host上运行的容器信息的,同样,在所有需要监控的服务器上执行下面的命令运行cAdvisor容器即可:
docker run -v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor google/cadvisor如果访问IP+8080断后的页面有这样的页面就表示cAdvrisor部署成功了。

Prometheus Server:是监控的主f服务,所以只需要在其中一台运行此容器,也可以多台机器部署。本案例中就以一台为例子:
[root@xjl ~]# docker run -d -p 9090:9090 --name prometheus --net=host prom/prometheus
#先基于prom/prometheus镜像随便运行一个容器,我们需要将其主配置文件复制一份进行更改
[root@xjl ~]# docker cp prometheus:/etc/prometheus/prometheus.yml /root/
#复制prometheus容器中的主配置文件到宿主机本地
[root@xjl ~]# docker rm -f prometheus
[root@xjl ~]# vim prometheus.yml
#找到如下行并修改
- targets: ['localhost:9090','localhost:8080','localhost:9100']
#修改为需要监控的数据端口。
[root@xjl ~]# docker run -d -p 9090:9090 -v /root/prometheus.yml:/etc/prometheus/prometheus.yml --name prometheus --net=host prom/prometheus
#执行上述命令,运行新的prometheus容器,并将刚刚修改的主配置文件挂载到容器中的指定位置
#以后若要修改主配置文件,则直接修改本地的即可。
#挂载主配置文件后,本地的和容器内的相当于同一份,在本地修改内容的话,会同步到容器中
Grafana容器监控数据可视化:可以将Prometheus Server的监控数据展示在相关的看板上。
[root@docker01 ~]# mkdir grafana-storage
[root@docker01 ~]# chmod 777 -R grafana-storage/
[root@docker01 ~]# docker run -d -p 3000:3000 --name grafana -v /root/grafana-storage:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=admin" grafana/grafana
#上述命令中的“-e”选项是为了设置默认的登录用户admin,密码为“123.com”。
#如果启动容器的过程中,提示iptables等相关的错误信息,
#则需要执行命令systemctl restart docker,重启docker服务,然后重新运行容器
#但是需要注意,若运行容器时没有增加“--restart=always”选项的话,
#那么在重启docker服务后,还需将所有容器手动重启。
#重启所有容器命令“docker ps -a -q | xargs docker start”

上述配置完成后,我们就需要配置它以什么样的形式来给我们展示了,可以自定义,但是很麻烦,也选择直接去grafana官网寻找现成的模板。
2.2 启动Alertmanager组件
Prometheus的告警方式有好几种方式,邮箱、钉钉、微信等,我这里选择邮箱的告警方式。本案例选择以邮件的方式和web-hook的方式来完成的相关的告警,其他的方式类似.大家可以自行探索。
[root@xjl ~]# docker run --name alertmanager -d -p 9093:9093 prom/alertmanager # 先简单运行一个容器
[root@xjl ~]# doc
ker cp alertmanager:/etc/alertmanager/alertmanager.yml /root # 将容器中的配置文件复制到本地
[root@docker01 ~]# docker rm -f alertmanager # 然后卸磨杀驴,把他给删
[root@docker01 ~]# vim alertmanager.yml
#配置文件中可以分为以下几组:
#global:全局配置。设置报警策略,报警渠道等;
#route:分发策略;
#receivers:接收者,指定谁来接收你发送的这些信息;
#inhibit_rules:抑制策略。当存在于另一组匹配的警报,抑制规则将禁用于一组匹配的警报
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 2m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qiye.aliyun.com:465'
smtp_from: 'your_email'
smtp_auth_username: 'your_email'
smtp_auth_password: 'email_passwd' # 邮箱授权码,不是登录密码
smtp_hello: 'your_email'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default # 优先使用default发送
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes: #子路由,使用email发送
- receiver: email
match_re:
serverity : email # label 匹配email
group_wait: 10s
receivers:
- name: 'default'
webhook_configs:
- url: http://localhost:8060/web-hook/
send_resolved: true # 发送已解决通知
- name: 'email'
email_configs:
- to: 'email@qq.com'
send_resolved: true
[root@docker01 ~]# docker run -d --name alertmanger -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml --restart=always prom/alertmanager
#运行新的alertmanager容器,并挂载更改后的配置文件 如果配置文件有错误,那么这个容器是运行不了的。prometheus与alertmanager通信">配置prometheus与alertmanager通信
vim prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.25.142:9093"] # 配置的Alertmanager的服务的ip+端口
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/usr/local/prometheus/rules/*.yaml" # 配置的相关的rules路径,这个容器的内部地址。启动的时候需要挂载到容器内,采用的正则表达式的方式来实现。
vim rules.yml
groups: # 报警组
- name: Node
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0 # 监控状态的值为 0时,说明服务异常,1为正常
for: 5m # 保持时间,上面的状态持续时间内都为 0 ,则触发告警
labels:
severity: error
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} of job {{ $labels.job }} 已经停止1分钟以上."



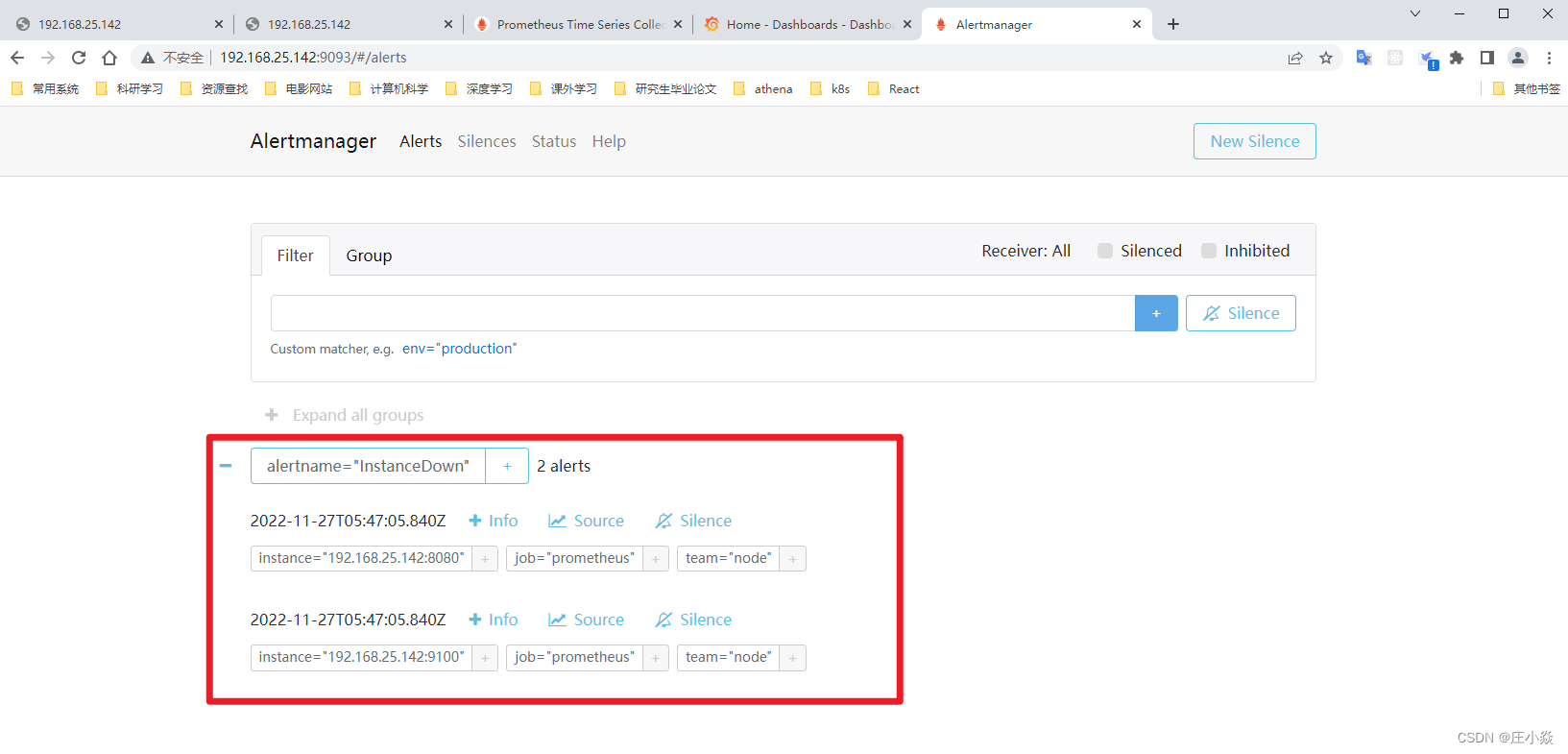
2.3 Prometheus+Alertmanager告警测试




三、Prometheus+Alertmanager+Jenkins自动化实战
四、基于Prometheus的自定义export监控服务实现
博文参考
Overview | Prometheus
docker容器部署Prometheus服务——云平台监控利器 - 腾讯云开发者社区-腾讯云